Eisenhower Medical Center, Riverside Community Hospital Palm Desert, CA
Akash Patel, MD1, Adewale Ajumobi, MD, FACG2 1Eisenhower Medical Center, Riverside Community Hospital, Palm Desert, CA; 2Eisenhower Health, Rancho Mirage, CA
Introduction: The application of large language models (LLMs) in healthcare has been a growing area of interest, particularly in providing patient-specific recommendations. This study evaluates the accuracy of different LLMs in recommending colonoscopy follow-up intervals based on the United States Multi-Society Task Force on Colorectal Cancer (USMSTF) 2020 guidelines. We compared ChatGPT 4 Omni, ChatGPT 4, and ChatGPT 3.5 to determine which model aligns most closely with the 2020 USMSTF guidelines.
Methods: We developed 15 hypothetical patient queries concerning colonoscopy follow-up intervals, varying in polyp size, number, and histology. Each query used the template: "During my colonoscopy, I had ____ polyps removed. When should I have my next colonoscopy? Please answer concisely and provide the interval in years only, based on current guidelines." These queries were submitted to each LLM, and the responses were compared against the USMSTF 2020 guidelines. Responses were classified as either aligned or not aligned with the guidelines. Search queries were performed on June 16, 2024.
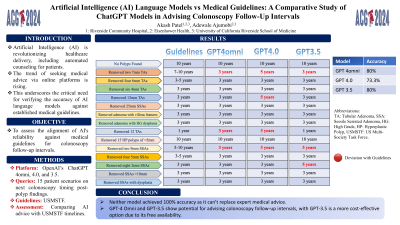
Results: ChatGPT 4 Omni provided 12 out of 15 correct answers, resulting in an accuracy of 80%. ChatGPT 4 followed with 11 out of 15 correct answers (73.3%), and ChatGPT 3.5 with 12 out of 15 correct answers (80%). The data suggest that both ChatGPT 4 Omni and ChatGPT 3.5 are the most accurate LLMs in recommending follow-up intervals based on the current guidelines.
Discussion: While both ChatGPT 4 Omni and ChatGPT 3.5 demonstrated high accuracy, neither achieved 100% alignment with the guidelines, indicating that none of the tested models can fully replace expert medical advice. This study highlights the potential of ChatGPT 4 Omni and ChatGPT 3.5 for integration into medical chatbots, given their relative accuracy. ChatGPT 3.5, being more cost-effective and freely available, may be particularly advantageous for widespread implementation. Future work should focus on refining these models to bridge the gap between AI recommendations and expert medical advice.
Note: The table for this abstract can be viewed in the ePoster Gallery section of the ACG 2024 ePoster Site or in The American Journal of Gastroenterology's abstract supplement issue, both of which will be available starting October 27, 2024.
Disclosures:
Akash Patel indicated no relevant financial relationships.
Adewale Ajumobi indicated no relevant financial relationships.
Akash Patel, MD1, Adewale Ajumobi, MD, FACG2. P2123 - AI Language Models vs Medical Guidelines: A Comparative Study of ChatGPT Models in Advising Colonoscopy Follow-Up Intervals, ACG 2024 Annual Scientific Meeting Abstracts. Philadelphia, PA: American College of Gastroenterology.

.jpg "Akash Patel, MD photo")