Erisa Gjoka, N/A1, Yuting Huang, MBBS, PhD2, Yichen Wang, MD3, Cary C. Cotton, MD, MPH4, Nicholas Shaheen, MD, MPH5, Swathi Eluri, MD, MSCR2 1Florida State University, Tallahassee, FL; 2Mayo Clinic, Jacksonville, FL; 3Mayo Clinic Florida, Jacksonville, FL; 4University of North Carolina at Chapel Hill School of Medicine, Chapel Hill, NC; 5Center for Esophageal Diseases and Swallowing, and Center for Gastrointestinal Biology and Disease, University of North Carolina School of Medicine, Chapel Hill, NC
Introduction: Internet search engines are increasingly relying on artificial intelligence (AI) platforms such as ChatGPT to generate responses. Little is known regarding the accuracy of these responses for questions related to Barrett’s esophagus (BE). The aim of this study is to evaluate responses of an AI Chatbot (ChatGPT) to BE clinical questions.
Methods: Common questions pertaining to BE as well as focused questions regarding diagnosis and management of BE were generated. Questions were posed to ChatGPT (GPT-4o) sequentially in a single session. Responses to individual questions were recorded. Responses were graded using previously used scoring guides on a 4-point scale: 3 = Correct and comprehensive; 2 = Correct but inadequate; 1 = Mixed correct and incorrect; and 0 = Completely incorrect or inadequate. Correctness of the response was based on degree of correlation with existing BE literature and guidelines. Inadequate responses had key missing information. Response quality was also assessed by the category of questions: General information, Diagnosis, and Management.
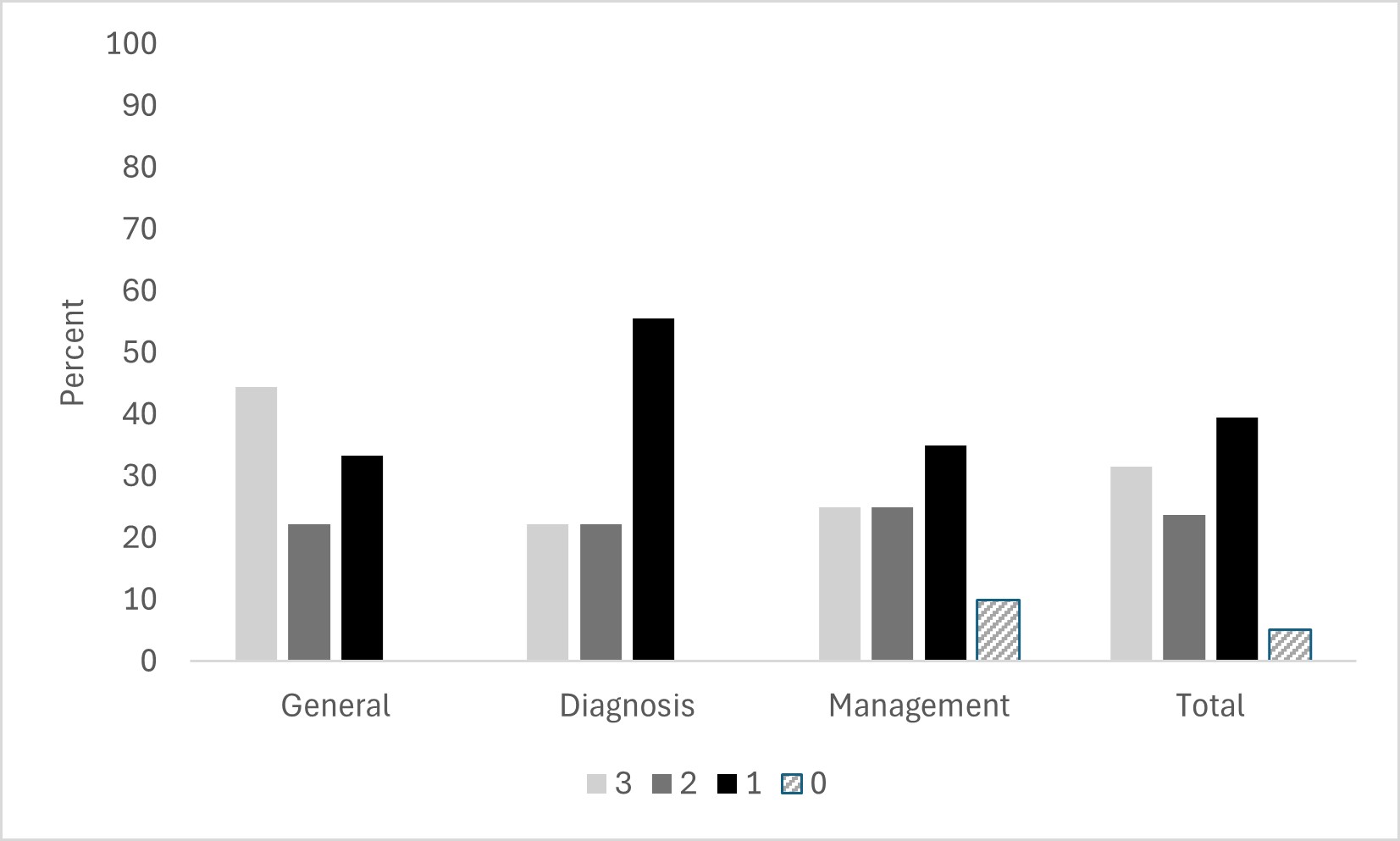
Results: A total of 38 questions were posed to GPT-4o. These questions were categorized as general information (n=9), diagnosis (n=9), and management (n=20) of BE. Of all questions, 31.6% (n=12) responses from GPT-4o were correct and comprehensive, 23.7% (n=9) were correct but inadequate, 39.5% (n=15) were mixed correct and incorrect, and 5.3% (n=2) were completely incorrect or inadequate. The greatest deficits in response accuracy and completeness were in questions pertaining to the diagnosis of BE with less than 25% of the responses being both correct and comprehensive (Figure). The two responses that were completely incorrect were focused on disease management with GPT-4o describing esophagectomy as management for BE with high grade dysplasia (HGD), and a response to a separate question recommending endoscopic surveillance for the same group. In all responses regarding management, endoscopic submucosal dissection (ESD) was not mentioned as a possible therapeutic modality for resection of visible lesions.
Discussion: GPT-4o’s responses for common BE questions showed that only 55% were correct, and a proportion of these were incomplete responses. This study highlights limitations in the latest ChatGPT model for use for BE patient education. Clinicians should be aware that patients accessing AI for BE education may have significant misunderstandings about their disease state.
Figure: Figure: Responses for questions regarding Barrett’s Esophagus graded for scientific correctness and completeness (3 = Correct and comprehensive; 2 = Correct but inadequate; 1 = Mixed correct and incorrect; 0 = Completely incorrect or inadequate)
Disclosures:
Erisa Gjoka indicated no relevant financial relationships.
Yuting Huang indicated no relevant financial relationships.
Yichen Wang indicated no relevant financial relationships.
Cary Cotton: Pentax – Grant/Research Support.
Nicholas Shaheen indicated no relevant financial relationships.
Swathi Eluri indicated no relevant financial relationships.
Erisa Gjoka, N/A1, Yuting Huang, MBBS, PhD2, Yichen Wang, MD3, Cary C. Cotton, MD, MPH4, Nicholas Shaheen, MD, MPH5, Swathi Eluri, MD, MSCR2. P3941 - Assessing the Accuracy of Responses by the Language Model ChatGPT 4.0 to Questions Regarding Barrett’s Esophagus, ACG 2024 Annual Scientific Meeting Abstracts. Philadelphia, PA: American College of Gastroenterology.