Chakib Battioui, PhD1, Pavel Brodskiy, PhD2, Klaus Gottlieb, MD, PhD1, Mohammad Haft-Javaherian, PhD2, Shrujal Baxi, MD3, Evan Yu, PhD2 1Eli Lilly and Company, Indianapolis, IN; 2Iterative Health Inc., Cambridge, MA; 3Iterative Health, Cambridge, MA
Introduction: The current use of trained central readers to evaluate the endoscopic Mayo Score (eMS) on endoscopy videos in Ulcerative Colitis (UC) trials is subject to disagreement, impacting the reliability of trial data. Efforts are underway to advance machine learning (ML) eMS prediction models to standardize evaluations. Heterogeneity in test datasets to evaluate the performance of these models limits performance comparisons. The objective of this study is to evaluate the performance of two original eMS prediction models against a uniform test set without development team access.
Methods: Mirikizumab is an IL-23 antagonist for moderate-to-severe UC in adults. Endoscopy data from the Mirikizumab trials was used to train and internally validate two original video-level eMS prediction models. 639 videos (approximately 25%) from the Phase 3 LUCENT 1 induction trial (NCT03518086) were held out of model training and used to evaluate the performance of both models on a uniform test set. All videos received a 2+1 centrally read eMS, per protocol. The distribution of eMS disease severity in the total video dataset was preserved in this subset, favoring patients with moderate-to-severe disease (82.2% eMS 2 or 3). Both eMS prediction models assessed all videos in this dataset independently. Statistical analysis evaluated model predicted eMS against the 2+1 score.
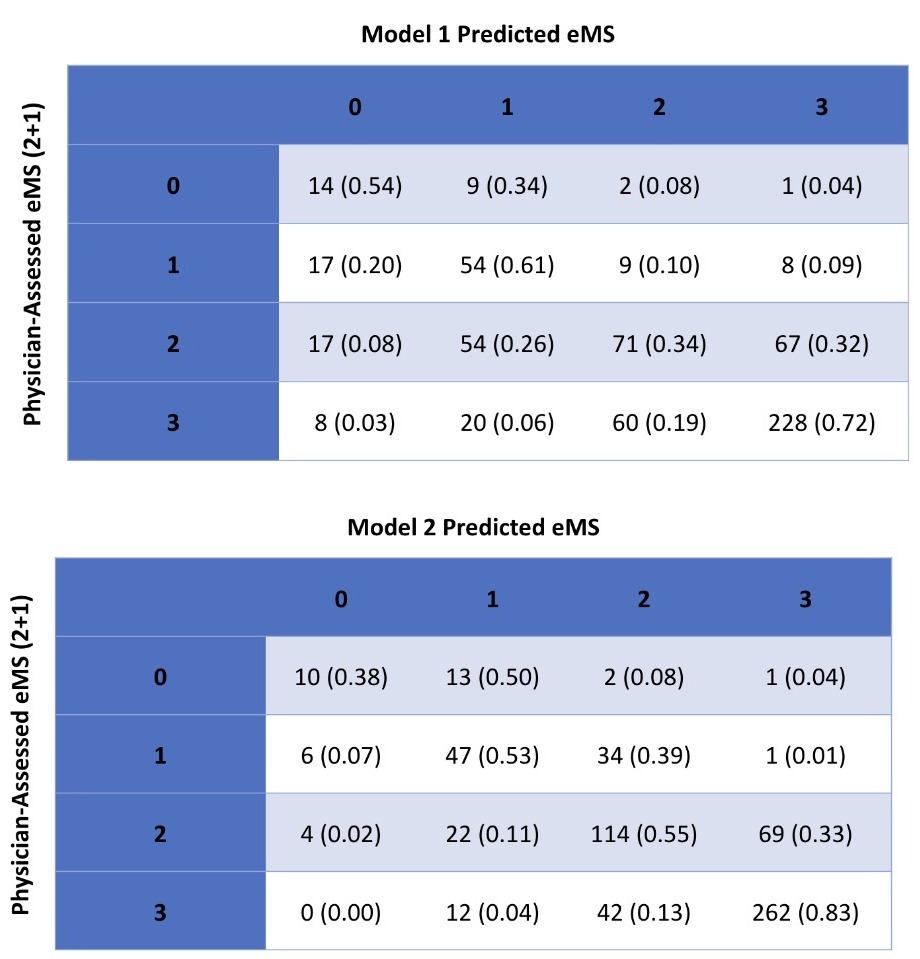
Results: Quadratic Weighted Kappa (QWK) was used for ordinal eMS evaluation. QWK for model 1 was 0.58 (95% confidence interval (CI), 0.54-0.61) and for model 2 was 0.70 (95% CI, 0.67-0.74). Recall for discrete eMS classes was evaluated for models 1 and 2, respectively: 54% vs 38% for eMS 0, 61% vs 53% for eMS 1, 34% vs 55% for eMS 2, 72% vs 83% for eMS 3. Accuracy of models 1 and 2 for endoscopic response (eMS 0, 1 vs 2, 3) was 81% and 88%, respectively. Accuracy of models 1 and 2 for endoscopic remission (eMS 0 vs 1, 2, 3) was 92% and 96%, respectively.
Discussion: This is to our knowledge the first evaluation of two different ML video-level eMS prediction models on the same holdout set. We found that both models perform well in assessing endoscopic response and remission. At a population level, model 2 performed slightly better; however, when looking at discrete eMS classes, model 1 performed better on eMS 0 and 1 cases, while model 2 performed better on eMS 2 and 3 cases. As ML eMS models are refined and mature, there is a need for standardized external test sets, providing unique insight into model performance to inform their use.
Figure: Figure 1. 4x4 confusion matrix comparing model 1 and 2 predictions and the physician-assessed eMS.
Disclosures:
Chakib Battioui: Eli Lilly & Company – Employee, Stock-publicly held company(excluding mutual/index funds).
Pavel Brodskiy: Iterative Health, Inc. – Employee, Stock Options.
Klaus Gottlieb: Eli Lilly & Company – Employee, Stock-publicly held company(excluding mutual/index funds).
Mohammad Haft-Javaherian: Iterative Health, Inc. – Employee, Stock Options.
Shrujal Baxi: Iterative Health, Inc. – Employee, Stock Options.
Evan Yu: Iterative Health, Inc. – Employee, Stock Options.
Chakib Battioui, PhD1, Pavel Brodskiy, PhD2, Klaus Gottlieb, MD, PhD1, Mohammad Haft-Javaherian, PhD2, Shrujal Baxi, MD3, Evan Yu, PhD2. P0661 - Head-to-Head Evaluation of Two Machine Learning Algorithms for Predicting Endoscopic Mayo Score in Ulcerative Colitis, ACG 2024 Annual Scientific Meeting Abstracts. Philadelphia, PA: American College of Gastroenterology.