P1777 - Addressing the Third Person in the Room: A Multidisciplinary Team Perspective on the Accuracy of AI Models to Deliver Information on Pancreatic Cancer and Reliable Reference
Chima Amadi, MD, MBA1, Daniela Ortega, MD1, Kennedy Watson, BS1, Hafsa M. Gundroo, MBBS1, Toni M. Jackson, DO2, Saurabh Chawla, MD3 1Morehouse School of Medicine, Atlanta, GA; 2Morehouse School of Medicine, Far Rockaway, NY; 3Emory University School of Medicine, Atlanta, GA
Introduction: The complexity and high mortality rate of pancreatic cancer (PC) warrant accurate and reliable information for both patients and healthcare providers. In the current era, artificial intelligence (AI) has emerged as a potential tool to address this need. However, the accuracy and reliability of AI-generated information on PC remain largely unknown. This study aims to evaluate the accuracy and credibility of AI-delivered information on PC from a multidisciplinary team (MT) perspective.
Methods: AI models you.com, Gemini, Copilot, and ChatGPT 3.5 were asked 13 questions related to PC. The questions were derived from the 2020 AGA Clinical Practice Update on PC Screening and commonly asked questions on Google Trends. Responses were recorded in April 2024 and rated using a 10-point Likert scale by a blinded MT consisting of specialists (two medical oncologists, two surgical oncologists, and two gastroenterologists) and non-specialists (two patient representatives and two primary care physicians). Each AI model provided references, which were reviewed and scored by two independent reviewers using a credibility scale. Performance differences were analyzed in Excel using ANOVA or t-test.
Results: The four AI models' average similar accuracy: you.com (7.36), Gemini (7.24), Copilot (7.26), and ChatGPT 3.5 (7.55) (ANOVA p = 0.60). However, their credibility scores differed significantly: you.com (4.57), Gemini (4.29), Copilot (3.64), and ChatGPT 3.5 (1.79) (ANOVA p < 0.001).
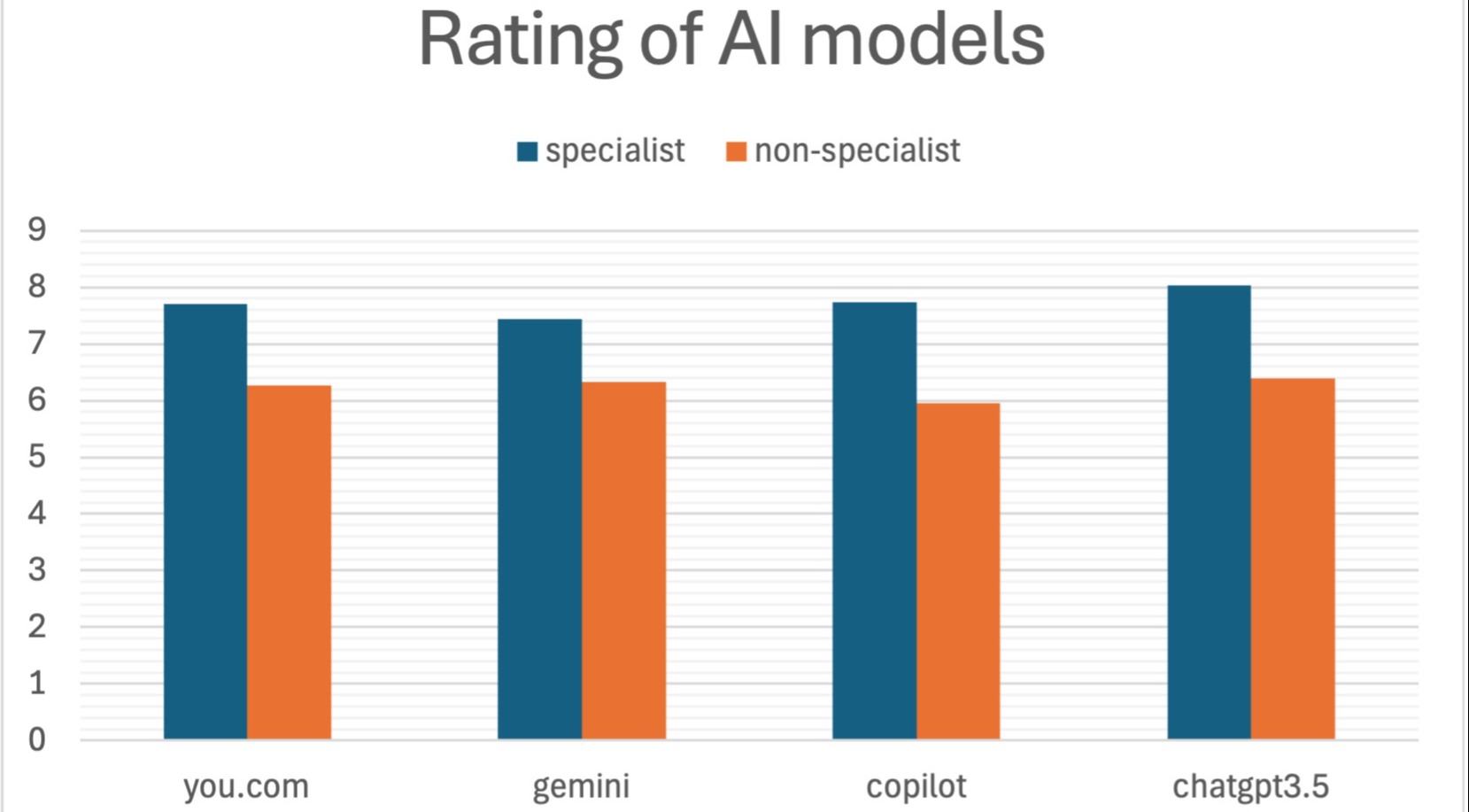
The MT's ratings also varied by individuals; Gastroenterologists provided the highest ratings (Mean 8.85 ± 1.01), followed by medical oncologists (7.92 ± 1.77), surgical oncologists (7.27 ± 1.03), primary care physicians (6.81 ± 1.41), and patient representatives (6.50 ± 0.79) (ANOVA p < 0.001). Overall, specialists rate AI models higher than non-specialists, 7.7 vs 6.2 (t-test < .0001).
Discussion: This study highlights the potential and limitations of the AI model in providing information on PC. While the AI models demonstrated similar accuracy (p = 0.60), there were significant differences in credibility scores, with you.com and Gemini scoring highest and ChatGPT 3.5 scoring lowest (p < 0.001). Overall, specialists rated AI models higher than non-specialists (7.7 vs 6.2, p < .0001). The speculated reason for this is more subject matter expertise among specialists. Thus, there is a need to improve non-specialist familiarity with pancreatic cancer. In addition, AI models need to improve the delivery of credible sources.
Figure: Overall, specialists rate AI models higher than non-specialists, 7.7 vs 6.2 (t-test p <.0001).
Disclosures:
Chima Amadi indicated no relevant financial relationships.
Daniela Ortega indicated no relevant financial relationships.
Kennedy Watson indicated no relevant financial relationships.
Hafsa Gundroo indicated no relevant financial relationships.
Toni Jackson indicated no relevant financial relationships.
Saurabh Chawla indicated no relevant financial relationships.
Chima Amadi, MD, MBA1, Daniela Ortega, MD1, Kennedy Watson, BS1, Hafsa M. Gundroo, MBBS1, Toni M. Jackson, DO2, Saurabh Chawla, MD3. P1777 - Addressing the Third Person in the Room: A Multidisciplinary Team Perspective on the Accuracy of AI Models to Deliver Information on Pancreatic Cancer and Reliable Reference, ACG 2024 Annual Scientific Meeting Abstracts. Philadelphia, PA: American College of Gastroenterology.