P1911 - Optical Accuracy of Artificial Intelligence Large Language Models in Classifying Colorectal Polyps Based on Shape, Size, and Histology, Using Endoscopic Images
Tarek Souaid, MD, MPH1, Anthony Kerbage, MD1, Carole Macaron, MD2, Carol A.. Burke, MD, FACG2, Carol Rouphael, MD2 1Cleveland Clinic, Cleveland, OH; 2Digestive Disease Institute, Cleveland Clinic, Cleveland, OH
Introduction: Artificial intelligence (AI) chatbots have shown promise in enhancing the experience of both physicians and patients in medicine. Recent advancements in optical technology for large language models (LLM) include image recognition. We sought to evaluate the optical accuracy of three advanced LLMs - open AI’s Generative Pre-trained Transformer-4o (GPT4o), Google’s Gemini 1.5 Pro, and Anthropic’s Claude 3 Sonnet - in characterizing colorectal polyps based on endoscopic images.
Methods: A sample of 20 endoscopic images of polyps was curated from an open-source gastrointestinal database, HyperKvasir, which includes unlabeled endoscopic images of colorectal polyps. Three experts independently classified the polyps based on three characteristics: shape (sessile, pedunculated), size (< 1cm, > 1cm), and histology (adenoma, hamartoma, serrated or inflammatory), and those were used as reference. Disagreement between experts resulted in the exclusion of 5 polyps, and only polyps thought to be adenomas were included (Table 1). We analyzed the accuracy of the three LLMs in characterizing the 15 polyps. A single standardized close-ended prompt was used for all LLMs, and images were introduced in the same order. The accuracy of different characteristics was evaluated for each LLM. In addition, accuracy for correct classification of all three characteristics combined and cumulative accuracy trend for each LLM were calculated.
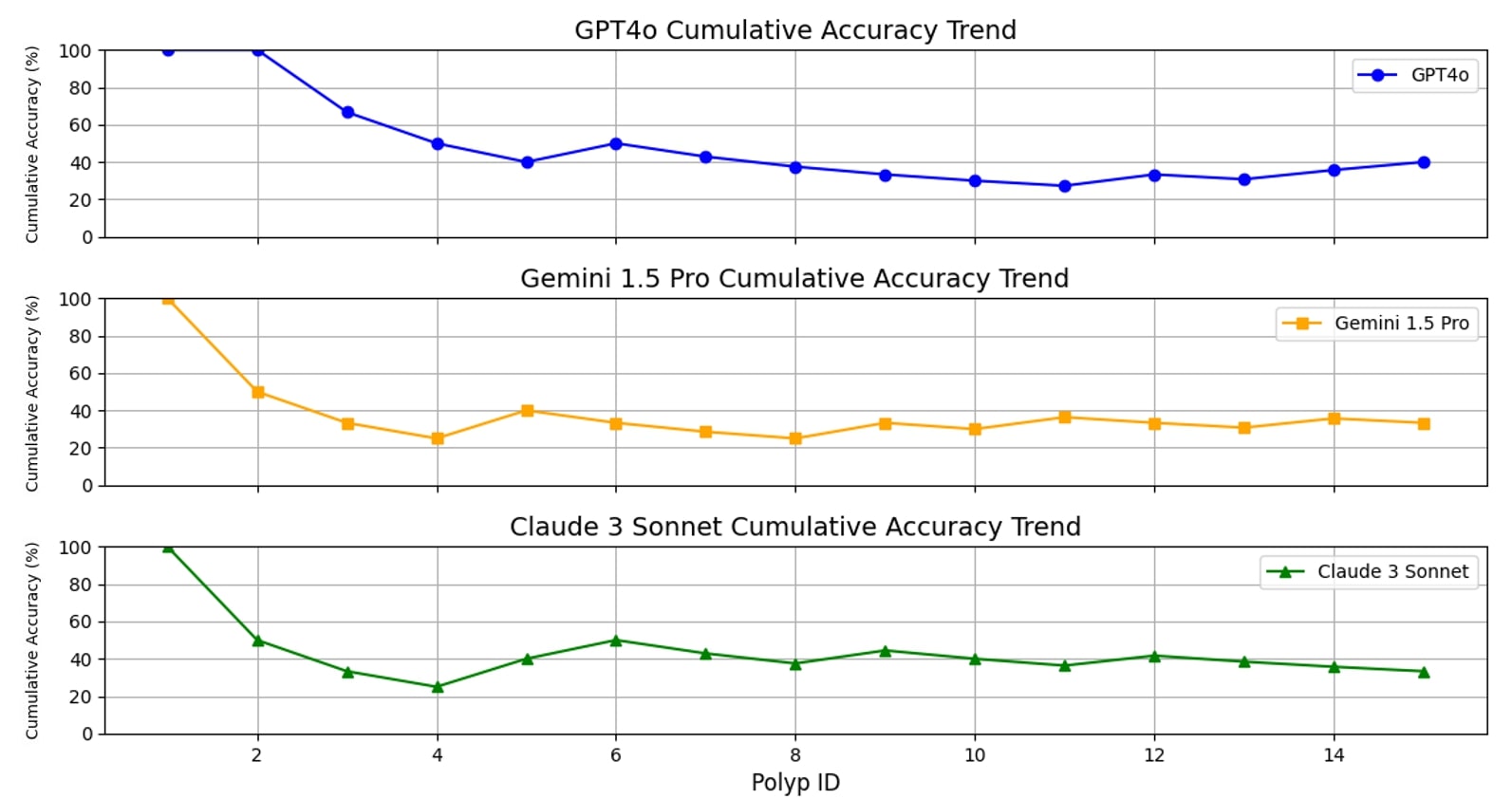
Results: LLM accuracy for shape was 60% for GPT4o, 67% for Gemini 1.5 Pro, and 47% for Claude 3 Sonnet. For size, GPT4o achieved 87% accuracy, Gemini 1.5 Pro 93%, and Claude 3 Sonnet 80%. For adenomatous histology, accuracy was 80% for GPT4o, 53% for Gemini 1.5 Pro, and 53% for Claude 3 Sonnet. The accuracy for correct classification of all three polyp characteristics combined was 40% for GPT4o, 33% for Gemini 1.5 Pro, and 33% for Claude 3 Sonnet. Cumulative accuracy trends for all three characteristics combined revealed that while GPT4o seemed to outperform the other LLMs, the performance trend of all LLMs was overall stable (Figure 1).
Discussion: While GPT4o performed better in the combined classification task, accuracy was suboptimal and all three LLMs are currently unreliable for polyp characterization. No learning curve was exhibited for any of the LLMs based on the cumulative accuracy trends. Our findings underscore that visual LLMs require further optimization and extensive training to effectively classify colorectal polyps and become useful in a clinical setting.
Figure: Figure 1 - Cumulative Accuracy Trends of LLMs for all Three Polyp Characteristics Combined
Note: The table for this abstract can be viewed in the ePoster Gallery section of the ACG 2024 ePoster Site or in The American Journal of Gastroenterology's abstract supplement issue, both of which will be available starting October 27, 2024.
Disclosures:
Tarek Souaid indicated no relevant financial relationships.
Anthony Kerbage indicated no relevant financial relationships.
Carole Macaron indicated no relevant financial relationships.
Carol Rouphael indicated no relevant financial relationships.
Tarek Souaid, MD, MPH1, Anthony Kerbage, MD1, Carole Macaron, MD2, Carol A.. Burke, MD, FACG2, Carol Rouphael, MD2. P1911 - Optical Accuracy of Artificial Intelligence Large Language Models in Classifying Colorectal Polyps Based on Shape, Size, and Histology, Using Endoscopic Images, ACG 2024 Annual Scientific Meeting Abstracts. Philadelphia, PA: American College of Gastroenterology.