Anthony Kerbage, MD1, Tarek Souaid, MD, MPH1, Carole Macaron, MD2, Carol A.. Burke, MD, FACG2, Carol Rouphael, MD2 1Cleveland Clinic, Cleveland, OH; 2Digestive Disease Institute, Cleveland Clinic, Cleveland, OH
Introduction: Large language models (LLMs) such as OpenAI's Generative Pre-Trained Transformer (GPT) models and Google's Gemini Pro 1.5 have been extensively studied for their accuracy in answering medical questions. Recently, these models have made significant advancements, particularly in their ability to process and interpret image inputs. In gastroenterology (GI), this development holds potential for integration into endoscopy, such as real-time report generation during procedures. We assess the accuracy of GPT-4o and Gemini Pro 1.5 in identifying typical upper and lower GI tract anatomical landmarks from images obtained during upper endoscopy and colonoscopy.
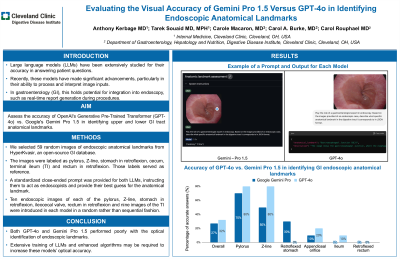
Methods: We selected 59 random images of different endoscopic anatomical landmarks from HyperKvasir, an open-source GI database. The images were labeled as pylorus, Z-line, stomach in retroflexion, cecum, terminal ileum (TI) and rectum in retroflexion. Those labels served as reference in our study. A standardized close-ended prompt was provided for both LLMs, instructing them to act as endoscopists and provide their best guess for the anatomical landmark (Figure 1). Ten endoscopic images of each of the pylorus, z-line, stomach in retroflexion, ileocecal valve, rectum in retroflexion and nine images of the TI were introduced in the model in a random rather than sequential fashion.
Results: The overall accuracy of GPT-4o was 32% vs. 27% for Gemini Pro 1.5. For upper GI tract anatomical landmarks, GPT-4o and Gemini Pro 1.5 had an overall accuracy of 53.3% and 50% respectively. Specifically, accuracy at identifying the pylorus was 80% for GPT-4o vs. 70% for Gemini Pro 1.5, 80% vs. 50% for Z-line (Figure 1) and 0% vs. 30% for the stomach in retroflexion. For the lower GI tract, GPT-4o achieved an overall accuracy of 10.3% vs. 3.4% for Gemini Pro 1.5. GPT-4o had an accuracy of 20% vs. 10% for Gemini Pro 1.5 for cecum identification, 10% vs. 0% for TI and both models failed to identify the rectum in retroflexion for all input images. Table 1 represents the different outputs generated.
Discussion: Both GPT-4o and Gemini Pro 1.5 performed poorly with the optical identification of typical GI tract endoscopic landmarks. Extensive training of these models and enhanced algorithms may be required to increase the models’ optical accuracy. If high accuracy is achieved, these freely available LLMs may hold potential for integration into GI endoscopy and trained to the needs of different endoscopic units.
Figure: Figure 1. Example of a Prompt and Output for Each Model
Note: The table for this abstract can be viewed in the ePoster Gallery section of the ACG 2024 ePoster Site or in The American Journal of Gastroenterology's abstract supplement issue, both of which will be available starting October 27, 2024.
Disclosures:
Anthony Kerbage indicated no relevant financial relationships.
Tarek Souaid indicated no relevant financial relationships.
Carole Macaron indicated no relevant financial relationships.
Carol Rouphael indicated no relevant financial relationships.
Anthony Kerbage, MD1, Tarek Souaid, MD, MPH1, Carole Macaron, MD2, Carol A.. Burke, MD, FACG2, Carol Rouphael, MD2. P2398 - Evaluating the Visual Accuracy of Gemini Pro 1.5 and GPT-4o in Identifying Endoscopic Anatomical Landmarks, ACG 2024 Annual Scientific Meeting Abstracts. Philadelphia, PA: American College of Gastroenterology.