P4915 - Artificial Intelligence Showdown in Gastroenterology: A Comparative Analysis of Large Language Models (LLMs) in Tackling Board-Style Review Questions
Feinberg School of Medicine, Northwestern University Chicago, IL
Kevin P. Shah, MD1, Shirin A. Dey, MD2, Shravya Pothula, MD3, Arnold Abud, MD1, Sukrit Jain, MD4, Aniruddha Srivastava, MD4, Sagar dommaraju, MD, MS5, Srinadh Komanduri, MD, MS1 1Feinberg School of Medicine, Northwestern University, Chicago, IL; 2McGaw Medical Center at Northwestern, Chicago, IL; 3University of Colorado, Aurora, CO; 4McGaw Medical Center of Northwestern University, Chicago, IL; 5Northwestern University, Chicago, IL
Introduction: Advancements in artificial intelligence (AI) have transformed the landscape of health care, through innovative technologies that augment clinical decision making. Tools such as large language models (LLMs) have the potential to improve medical education and help with diagnostic and treatment considerations in gastroenterology (GI). This study aims to compare the effectiveness of 2 LLMs, including Chat Generative Pre-Trained Transformer (ChatGPT v4o) and Advanced Gemini, in answering board-style GI questions.
Methods: A total of 104 questions from the Digestive Diseases Self-Education Platform (DDSEP) question bank were randomly selected across topic areas including esophagus, stomach and duodenum, pancreas, biliary tract, liver, small intestine, colon, and GI cancers. Both LLMs were instructed to choose the best answer and rate confidence on a scale of 1-5 (1 being least confident, 5 being most confident). For each incorrect answer, the LLM was given a second opportunity. Quantitative and qualitative data were obtained. Proportions were compared using a z-test and confidence was compared using a t-test.
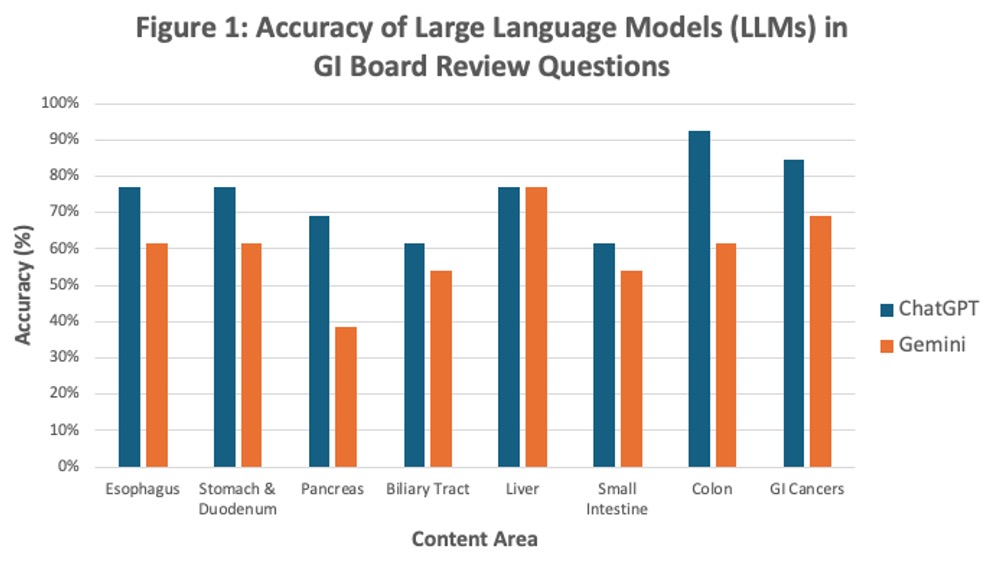
Results: Of 104 total DDSEP questions, 29 (27.9%) had images (endoscopic, radiologic, or lab values in tables). ChatGPT demonstrated more accuracy (75% vs 59.1%, p-value 0.018) and confidence (4.95 vs 4.44, p-value < 0.001) compared to Gemini when answering gastroenterology board style DDSEP questions on the first attempt. For questions answered incorrectly, ChatGPT and Gemini both answered 13/26 (50%) and 21/42 (50%) questions accurately on the second attempt. Of missed questions, 42% were missed by both LLMs, 13% were missed by ChatGPT, and 46% were missed by Gemini. Figure 1 shows accuracy of ChatGPT and Gemini across various topic areas. Observationally, both LLMs were able to interpret tables (of lab values) and endoscopic images (although with limitations), but ChatGPT appeared to be more comfortable interpreting radiologic images, including computed tomography and cholangiography. At times, both LLMs faced challenges with synthesis and clinical reasoning, especially when choosing between multiple answers that could be correct.
Discussion: ChatGPT outperforms Gemini in answering GI board review questions. This study highlight the potential of LLMs as educational tools and clinical resources for physicians. However, additional research and development is necessary to ensure LLMs provide end-users answers and explanations using appropriate and accurate clinical reasoning.
Figure: Figure 1. Accuracy of Large Language Models (LLMs) in GI Board Review Questions
Note: The table for this abstract can be viewed in the ePoster Gallery section of the ACG 2024 ePoster Site or in The American Journal of Gastroenterology's abstract supplement issue, both of which will be available starting October 27, 2024.
Disclosures:
Kevin Shah indicated no relevant financial relationships.
Shirin Dey indicated no relevant financial relationships.
Shravya Pothula indicated no relevant financial relationships.
Arnold Abud indicated no relevant financial relationships.
Sukrit Jain indicated no relevant financial relationships.
Aniruddha Srivastava indicated no relevant financial relationships.
Sagar dommaraju indicated no relevant financial relationships.
Srinadh Komanduri indicated no relevant financial relationships.
Kevin P. Shah, MD1, Shirin A. Dey, MD2, Shravya Pothula, MD3, Arnold Abud, MD1, Sukrit Jain, MD4, Aniruddha Srivastava, MD4, Sagar dommaraju, MD, MS5, Srinadh Komanduri, MD, MS1. P4915 - Artificial Intelligence Showdown in Gastroenterology: A Comparative Analysis of Large Language Models (LLMs) in Tackling Board-Style Review Questions, ACG 2024 Annual Scientific Meeting Abstracts. Philadelphia, PA: American College of Gastroenterology.



.jpg "Kevin P. Shah, MD photo")