Introduction: Chat GPT and Gemini are advanced Artificial Intelligence (AI) models that are being integrated into medicine. Early versions of Chat GPT did not meet ACG board standards. The latest versions have advanced but have yet to be compared to human gastroenterologist expertise. This study evaluates these AI models in answering ACG board review questions compared to fellows and specialists. It explores their potential to enhance medical education diagnostic accuracy and revolutionize gastroenterology training and practice.
Methods: Experts curated ACG board review questions by difficulty. After randomization, 15 questions were distributed to experts in General Gastroenterology (GG), inflammatory bowel disease (IBD), Nutrition, Pancreaticobiliary and Endoscopy (PBE), and Hepatology (HP). Timed responses were evaluated blindly. These answers were compared to AI models' responses, including Chat GPT 3.5, 4.0, 4o, and Gemini. The most accurate model was analyzed for consistency. References used by AI models were examined. The analysis included descriptive statistics, subgroup analysis, and correlation analysis.
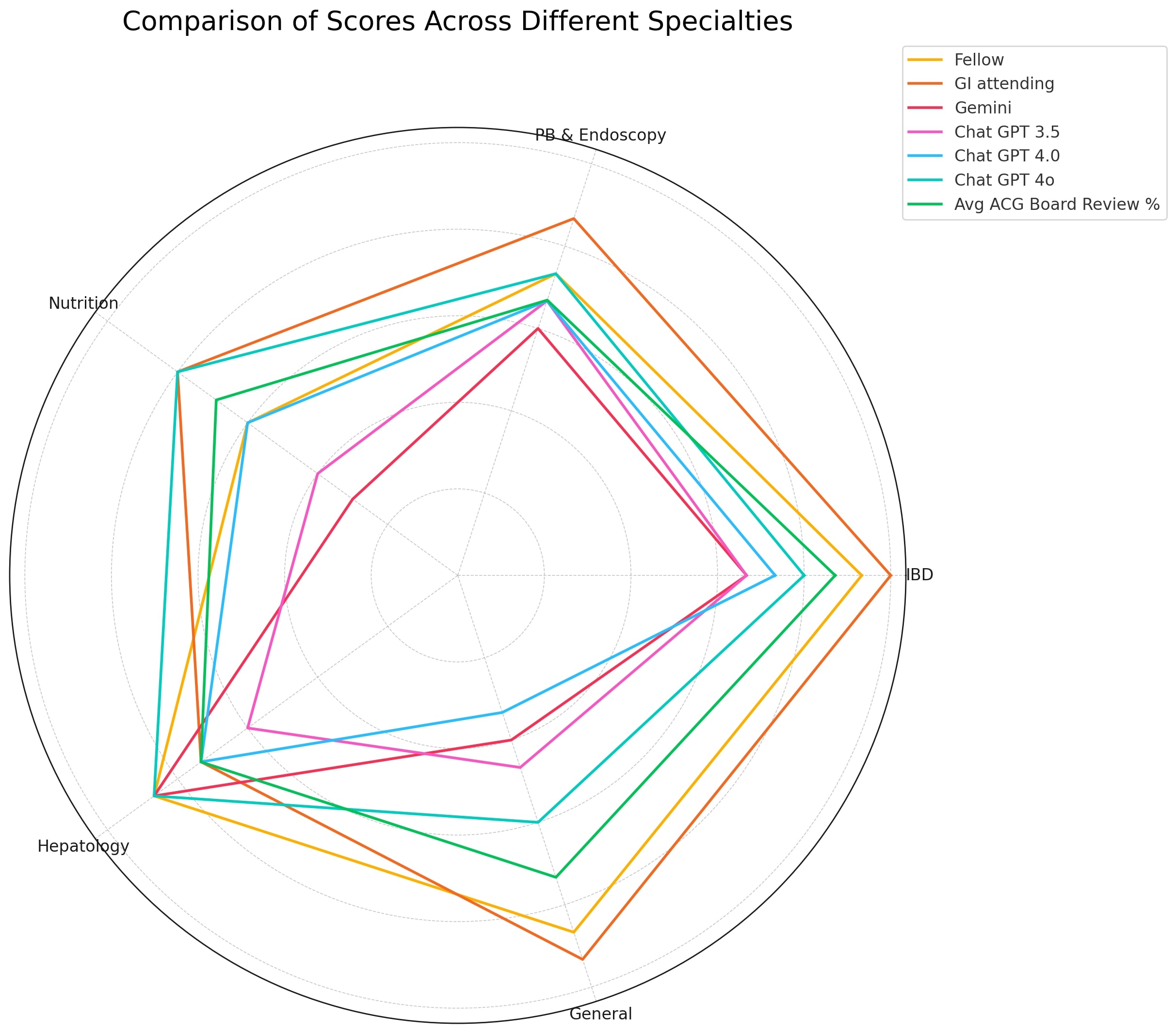
Results: Fellows' mean score was 80 %(95% CI: 60-93.3), while attendings scored 86.66% (73.3-100). Chat GPT 3.5 had the lowest mean score (56.01%), while Chat GPT 4o had the highest (76%), still below fellows and specialists but slightly above the average ACG score (73.94%). Specialists took 52 seconds to answer, less than fellows' 60 seconds. Chat GPT 4o showed good consistency in IBD and moderate in PBE but poor in Nutrition, HP, and GG. Gemini and Chat GPT 4o performed similarly in HP. AI models generally scored lower than specialists, except in HP, where Chat GPT 4o outperformed specialists. Chat GPT 4o outperformed other AI models but lacked consistency—positive correlation between fellows and attendings' scores (r=0.75 and r=0.64)(Table).
Discussion: Using ACG board review questions, this study evaluated Chat GPT and Gemini AI models against gastroenterology fellows and attendings. Chat GPT 4o, the best AI, scored 76%, below fellows' 80% and attendings' 86.66%. AI performance varied, excelling in HP but inconsistent in others. Human specialists answered more quickly and accurately, highlighting the current superiority of human expertise. AI shows promise, especially in targeted areas, but must match human experts' nuanced understanding and clinical judgment. Continuous AI advancements are essential for effective medical education and practice integration.
Figure: Radar chart of correctly answered questions by categories by ChatGPT, Gemini, GI Fellows, Subspeciality attendings and current ACG board review assessment.
Note: The table for this abstract can be viewed in the ePoster Gallery section of the ACG 2024 ePoster Site or in The American Journal of Gastroenterology's abstract supplement issue, both of which will be available starting October 27, 2024.
Disclosures:
Gautam Maddineni indicated no relevant financial relationships.
Zaid Ansari indicated no relevant financial relationships.
Akram Ahmad indicated no relevant financial relationships.
Tilak Shah indicated no relevant financial relationships.
Asad Ur Rahman: Abbvie – Speakers Bureau.
Fernando Castro indicated no relevant financial relationships.
Gautam Maddineni, MD1, Zaid Ansari, MD2, Akram Ahmad, MBBS3, Tilak Upendra. Shah, MD3, Asad Ur Rahman, MD3, Fernando NA. Castro, MD3. P4911 - AI vs Experts: Evaluating Chat GPT and Gemini in Gastroenterology Board Review Mastery, ACG 2024 Annual Scientific Meeting Abstracts. Philadelphia, PA: American College of Gastroenterology.