P2553 - Visual Accuracy of Gemini Pro 1.5 and GPT-4o in Determining Ulcerative Colitis Severity Based on Endoscopic Images Using the Modified Mayo Endoscopic Score
Tarek Souaid, MD, MPH1, Anthony Kerbage, MD1, Carole Macaron, MD2, Carol A.. Burke, MD, FACG2, Carol Rouphael, MD2 1Cleveland Clinic, Cleveland, OH; 2Digestive Disease Institute, Cleveland Clinic, Cleveland, OH
Introduction: Artificial intelligence (AI) and large language models (LLMs) have seen notable advances in recent years, and their accuracy in answering medical questions has been previously studied. Open AI’s Generative Pre-trained Transformer (GPT) and Google’s Gemini are two LLMs that have shown substantial progress in optical recognition tasks. We evaluate the performance of Gemini Pro 1.5 and GPT-4o in classifying ulcerative colitis (UC) severity based on endoscopic images, using the Modified Mayo Endoscopic Score (MMES).
Methods: HyperKvasir, an open-source gastrointestinal database, includes endoscopic UC images categorized by MMES. From this database, we curated 10 labeled images for each MMES grade (1, 2, and 3), for a total of 30 images. The MMES labels provided by two independent experts in the HyperKvasir dataset served as reference. A standardized close-ended prompt was engineered for both models, instructing them to assume the role of a UC expert and provide their best guess for the MMES for each UC endoscopic image. Image inputs were introduced in the same order for both models: 10 consecutive images for MMES grade 1, 10 consecutive images for MMES grade 2, and 10 consecutive images for MMES grade 3. The primary outcome measure was the accuracy of each model in matching the MMES reference scores. Secondary analysis included visualizing the performance of each model with confusion matrices.
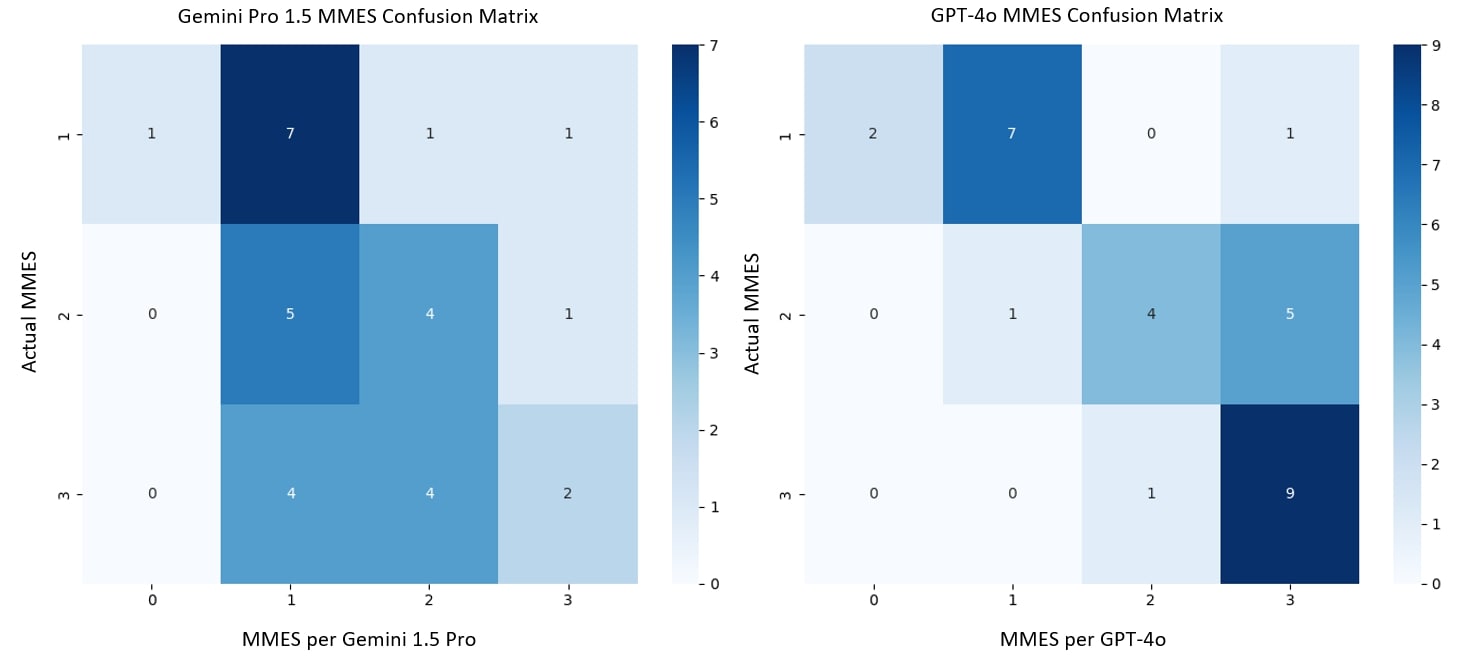
Results: The overall accuracy of GPT-4o was 67% vs. 43% for Gemini Pro 1.5. Both models achieved an identical accuracy of 70% for MMES 1 and 40% for MMES 2. For MMES 3, GPT-4o outperformed Gemini Pro 1.5, achieving an accuracy of 90% compared to Gemini Pro 1.5's 20%. Confusion matrix analysis revealed that GPT-4o had fewer misclassifications and better consistency in its scoring for MMES 3 compared to Gemini Pro 1.5 (Figure 1).
Discussion: While GPT-4o outperformed Gemini Pro 1.5 in accurately scoring MMES 3 UC cases, both models performed equally for MMES 1 and 2. The overall accuracy of both models was suboptimal, indicating neither model is currently reliable for assessing UC endoscopic severity. Further optimization and more comprehensive training are needed for these visual LLMs to adequately grade UC severity based on endoscopy pictures.
Figure: Figure 1: Confusion Matrices of Gemini Pro 1.5 and GPT-4o
- MMES: Modified Mayo Endoscopic Score - Actual MMES: MMES labels provided by experts in the HyperKvasir dataset that serve as reference
Disclosures:
Tarek Souaid indicated no relevant financial relationships.
Anthony Kerbage indicated no relevant financial relationships.
Carole Macaron indicated no relevant financial relationships.
Carol Rouphael indicated no relevant financial relationships.
Tarek Souaid, MD, MPH1, Anthony Kerbage, MD1, Carole Macaron, MD2, Carol A.. Burke, MD, FACG2, Carol Rouphael, MD2. P2553 - Visual Accuracy of Gemini Pro 1.5 and GPT-4o in Determining Ulcerative Colitis Severity Based on Endoscopic Images Using the Modified Mayo Endoscopic Score, ACG 2024 Annual Scientific Meeting Abstracts. Philadelphia, PA: American College of Gastroenterology.